Deep Learning 101: What even is a Neural Network?
The Perceptron and the Multi-Layer Perceptron
As Machine Learning and Artificial Intelligence and the myriad techniques that make up these umbrella terms have evolved, so have our data related needs. One technique that has increased in popularity over the past several years is the Neural Network, which is a Deep Learning technique.
Deep Learning is a faction of Machine Learning, with “Deep” representing the complexity of these models (including the Neural Network). Neural Networks are constructed as stacks of layers from which hierarchical representations of the input data can be extracted. The more layers a Neural Network has, the deeper the model is. Before jumping into what a Neural Network is, let’s review some foundational concepts.
The Perceptron
The complexity of a Neural Network comes from the interaction of relatively simple component parts, including the ‘neuron’ and ‘perceptron’. The perceptron is the most basic processing unit in a Neural Network, and is often framed as analogous to a biological neuron. Just like a biological neuron, a perceptron has input connections that are used to receive data (i.e. external stimuli). The perceptron performs internal calculations, just like the human brain, and generates some output. In a Neural Network, the perceptron is merely a foundational mathematical function that is codified with a futuristic name. In this case, that calculation can be thought of as a weighted sum of the input values.

The weighing assigned to each input value comes from the assigned weights of each of the input connections. More simply, each input value will have more or less importance depending on the weight that it has been assigned. Those weights, in turn, become the parameters for the model, and then later they will be tuned so the model can learn appropriately.
If you’re familiar with foundational techniques like regression and classification, you might have noticed that a perceptron is not all that different from a regression or classification model. Essentially, we have some input values which define either a hyperplane or a decision boundary (aka a line) and we can vary the slope or angle of the line by tuning (aka changing) the parameters.

If you’re familiar with regression, you may remember the concept of an “intercept”. If you’re not familiar, an interest is essentially the value of the outcome variable when our dependent variables equal some value (typically 0 or the mean). Perceptrons have a “intercept” as well - except it’s called the “bias”. With Neural Networks the bias is modeled as an additional input connect to the perceptron, and which we can use to alter the behavior of the perceptron.
Neural Networks, simply, are made up of interconnected perceptrons. However, unlike linear regression or linear transformation based classifiers, interconnected perceptrons need to be able to perform non-linear functions. Non-linear functions can be thought of, most simply, as functions that don’t result in a straight line separating the input data.
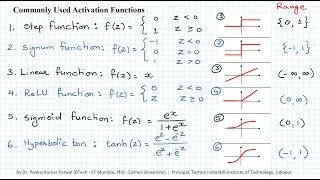
Single perceptrons can only solve linear functions. We won’t get into why during this article, but if you’re interested comment below. Since perceptrons can only solve linear functions, we’ll need to apply an “Activation Function” to the neurons, which will allow non-linearities to be introduced into the model. There are a handful of different activation functions (again, comment below if you want a more detailed breakdown of these), each with its own use case. By combining multiple perceptrons with activation functions to create a Neural Network, the model can now work with non-linearly separable data.
The Multi-Layer Perceptron (MLP)
An important point in all of this is that, in the real world, non-linearly separable data is very common. Therefore, we’ll typically combine several layers of linear combinations to create a network called a Multi-Layer Perceptron (MLP). There are three types of layers in an MLP.
Input layer. Contains the input data
Hidden layer(s). Layers between the input and the output. This is where all computation is done. The number of hidden layers defines how “deep” the neural network is. More hidden layers = a deeper model.
Output layer. Contains the results of the function modeled by the neural network applied to the input values.

Given the Multi Layer Perceptron in the graphic above, we can define the formulas used in our model. We’ll discuss this more in depth in a future article, but for now just know that each layer holds it’s own set of parameters and complexities which affect the efficacy and interpretability of the model. A deeper model isn’t always more effective or more useful.
Conclusion
Neural Networks are made up of layers of stacked neurons. This allow us to represent data in hierarchical levels. However, even Neural Networks have limitations. We have discussed the limitations of the perceptron model involving non-linearly separable data, and how we can alleviate this by connecting several neurons and activation functions.
This article covered MultiLayer Perceptrons as well, and in future articles we will discuss other types of Neural Networks like Recurrent or Convolutional Neural Networks and how to train Neural Network models.
Want a deep dive into this or related topics, need in depth answers or walkthroughs of how to implement or design neural networks? Send us an email to inquire about hands on consulting or workshops!